Регулярные выражения
Регулярные выражения (regular expressions) - это текстовый шаблон, который соответствует какому-то тексту. И всё? Да, это всё, для чего они нужны.
Что можно делать с помощью регулярных выражений:
- Проверять то, что вводит пользователь, чтобы быть уверенным в правильности данных (например, правильно ли пользователь ввёл email или ip-адрес).
- Разбирать большой текст на меленькие кусочки (например, выбирать данные из большого лога).
- Делать замены по шаблону (например, убирать непечатаемые символы из XML).
- Показывать невероятную крутость тем, кто не знает регулярных выражений.
Большинство современных языков программирования и текстовых редакторов (по моему личному мнению) поддерживают регулярные выражения. Поддержим их и мы.
/Быть или не быть/ugi ¶
Синтаксис регулярных выражений прост и логичен. Он разделяется на символ-разделитель (он идёт в начале и конце выражения, обычно это /), шаблон поиска и необязательные модификаторы.
Формальный синтаксис такой:
[разделитель][шаблон][разделитель][модификаторы]
Разделителем может быть любой символ, но обычно это / или ~. Важно лишь то, чтобы шаблон начинался и заканчивался одним и тем же разделителем. В самом конце регулярных выражений идут модификаторы, которые нужны, чтобы менять логику работы шаблонов (например делать регистронезависимый поиск).
Давайте разберём выражение /Быть или не быть/ugi:
/ - начальный символ-разделитель
Быть или не быть - шаблон поиска
/ - конечный символ-разделитель
ugi - модификаторы (UTF-8, global, case insensitive)
Данное регулярное выражение будет искать текст Быть или не быть не зависимо от регистра по всему тексту неограниченное количество раз. Модификатор u нужен для того, чтобы явно указать, что текст у нас в юникоде, то есть содержит символы, отличные от латиницы. Модификатор i включает регистронезависимый поиск. Модификатор g указывает поисковику идти до победного конца, иначе он остановится после первого удачного совпадения.
"Петя любит Дашу".replace(/Дашу|Машу|Сашу/, "Катю") ¶
Не трудно догадаться, что результатом работы js-выражения выше будет текст "Петя любит Катю". Даже, если Петя неровно дышит к Маше или Саше, то результат всё равно не изменится.
Рассмотрим базовые спец. символы, которые можно использовать в шаблонах:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \ | Символ экранирования или начала мета-символа | /путь\/к\/папке/ | Надёт текст путь/к/папке |
| ^ | Признак начала строки | /^Дом/ | Найдёт все строки, которые начинаются на Дом |
| $ | Признак конца строки | /родной$/ | Найдёт все строки, которые заканчиваются на родной |
| . | Точка означает любой символ, кроме перевода строки | /Петя ..бит Машу/ | Найдёт как Петя любит Машу, так и Петя губит Машу |
| | | Означает ИЛИ | /Вася|Петя/ | Найдёт как Васю, так и Петю |
| ? | Означает НОЛЬ или ОДИН раз | /Вжу?х/ | Найдёт Вжх и Вжух |
| * | Означает НОЛЬ или МНОГО раз | /Вжу*х/ | Найдёт Вжх, Вжух, Вжуух, Вжууух и т.д. |
| + | Означает ОДИН или МНОГО раз | /Вжу+х/ | Найдёт Вжух, Вжуух, Вжууух и т.д. |
Помимо базовых спец. символов есть мета-символы (или мета-последовательности), которые заменяют группы символов:
| Символ | Описание | Пример использования | Результат |
|---|---|---|---|
| \w | Буква, цифра или _ (подчёркивание) | /^\w+$/ | Соответствует целому слову без пробелов, например _Вася333_ |
| \W | НЕ буква, цифра или _ (подчёркивание) | /\W\w+\W/ | Найдёт полное слово, которое обрамлено любыми символами, например @Петя@ |
| \d | Любая цифра | /^\d+$/ | Соответствует целому числу без знака, например 123 |
| \D | Любой символ НЕ цифра | /^\D+$/ | Соответствует любому выражению, где нет цифр, например Петя |
| \s | Пробел или табуляция (кроме перевода строки) | /\s+/ | Найдёт последовательность пробелов от одного и до бесконечности |
| \S | Любой символ, кроме пробела или табуляции | /\s+\S/ | Найдёт последовательность пробелов, после которой есть хотя бы один другой символ |
| \b | Граница слова | /\bдом\b/ | Найдёт только отдельные слова дом, но проигнорирует рядом |
| \B | НЕ граница слова | /\Bдом\b/ | Найдёт только окночние слов, которые заканчиваются на дом |
| \R | Любой перевод строки (Unix, Mac, Windows) | /.*\R/ | Найдёт строки, которые заканчиваются переводом строки |
Нужно отметить, что спец. символы \w, \W, \b и \B не работают по умолчанию с юникодом (включая кириллицу). Для их правильной работы нужно указывать модификатор u. К сожалению, на окончание 2019 года JavaScript не поддерживает регулярные выражения для юникода даже с модификатором, поэтому в js эти мета-символы работают только для латиницы.
Ещё регулярные выражения поддерживают разные виды скобочек:
| Выражение | Описание | Пример использования | Результат |
|---|---|---|---|
| (...) | Круглые скобки означают под-шаблон, который идёт в результат поиска | /(Петя|Вася|Саша) любит Машу/ | Найдёт всю строку и запишет воздыхателя Маши в результат поиска под номером 1 |
| (?:...) | Круглые скобки с вопросом и двоеточием означают под-шаблон, который НЕ идёт в результат поиска | /(?:Петя|Вася|Саша) любит Машу/ | Найдёт только полную строку, воздыхатель останется инкогнито |
| (?P<name>...) | Задаёт имя под-шаблона | /(?P<воздыхатель>Петя|Вася|Саша) любит Машу/ | Найдёт полную строку, а воздыхателя запишет в результат под индексом 1 и 'воздыхатель' |
| [abc] | Квадратные скобки задают ЛЮБОЙ СИМВОЛ из последовательности (включая спец. символы \w, \d, \s и т.д.) | /^[123]+$/ | Соответствует любому выражению 323323123, но не 54321 |
| [a-я0-9] | Если внутри квадратных скобок указать минус, то это считается диапазоном | /[A-Za-zА-Яа-яЁё0-9_]+/ | Аналог /\w/ui для JavaScript |
| [abc-] | Если минус является первым или последним символом диапазона, то это просто минус | /[0-9+-]+/ | Найдёт любое целое числое с плюсом или минусом (причём не обязательно, чтобы минус или плюс были спереди) |
| [^...] | Квадратные скобки с "крышечекой" означают любой символ НЕ входящий в диапазон | /[^a-zа-я0-9 ]/i | Найдёт любой символ, который не является буквой, числом или пробелом |
| [[:class:]] | Квадратные скобки в квадратных скобках задают класс символов (alnum, alpha, ascii, digit, print, space, punct и другие) | /[^[:print:]]+/ | Найдёт последовательность непечатаемых символов |
| {n} | Фигурные скобки с одним числом задают точное количество символов | /\w+н{2}\w+/u | Найдёт слово, в котором две буквы н |
| {n,k} | Фигурные скобки с двумя числами задают количество символов от n до k | /\w+н{1,2}\w+/u | Найдёт слово, в котором есть одна или две буквы н |
| {n,} | Фигурные скобки с одним числом и запятой задают количество символов от n до бесконечности | /\w+н{3,}\w+/u | Найдёт слово, в котором н встречается от трёх и более раз подряд |
Как правильно писать регулярные выражения ¶
Прежде, чем садиться и писать регулярно выраженного кракена, подумайте, что именно вы хотите сделать. Регулярное выражение должно начинаться с мысли "Я хочу найти/заменить/удалить то-то и то-то". Затем вам нужен исходный текст, который содержит как ПРАВИЛЬНЫЕ, так и НЕправильные данные. Затем вы открываете https://regex101.com/, вставляете текст и начинаете писать регулярное выражение. Этот замечательный инструмент укажет и покажет все ошибки, а также подсветит результаты поиска.
Для примера возьмём валидацию ip-адреса. Первая мысль должна быть: "Я хочу валидировать ip-адрес. А что такое ip-адрес? Из чего он состоит?". Затем нужен список валидных и невалидных адресов:
# Валидные адреса
0.0.0.0
0.1.2.3
99.99.99.99
199.199.199.199
255.255.255.255
# Невалидные адреса
01.01.01.01
.1.2.3
1.2.3.
255.0.0.256
Валидный адрес должен содержать четыре числа (байта) от 0 до 255. Если он содержит число больше 255, это уже ошибка. Если бы мы делали валидацию на каком-либо языке программирования, то можно было бы разбить выражение на четыре части и проверить каждое число отдельно. Но регулярные выражения не поддерживают проверки больше или меньше, поэтому придётся делать по-другому.
Для начала упростим задачу: будем валидировать не весь ip-адрес, а только один байт. А байт это всегда есть либо одно-, либо дву-, либо трёхзначное число. Для одно- и двузначного числа шаблон очень простой - любая цифра. А вот для трёхзначного числа первая цифра либо единица, либо двойка. Если первая цифра единица, то вторая и третья могут быть от нуля до девяти. Если же первая цифра двойка, то вторая может быть только от нуля до пяти. Если первая цифра двойка и вторая пятёрка, то третья может быть только от ноля до пяти. Давайте формализуем:
# Валидация байта
от 0 до 9 \d
от 10 до 99 [1-9]\d
от 100 до 199 1\d\d
от 200 до 249 2[0-4]\d
от 250 до 255 25[0-5]
Теперь, зная все диапазоны байта, можно объединить их в одно выражение через вертикальную палочку | (ИЛИ):
\b(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\b
Обратите внимание, что я использовал границу слова \b, чтобы искать полные байты. Пробуем регулярку в деле:
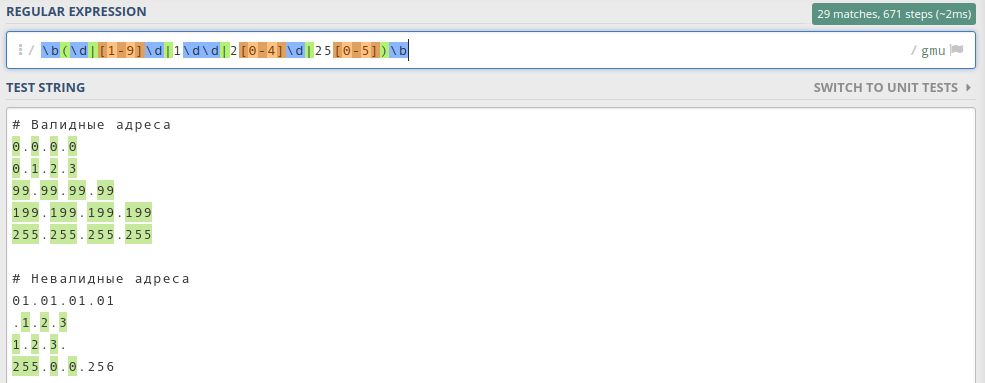
Как видим, все байты стали зелёненькими. Это значит, что мы на верном пути.
Осталось дело за малым: сделать так, чтобы искать четыре байта, а не один. Нужно учесть, что байты разделены тремя точками. То есть мы ищем три байта с точкой на конце и один без точки:
(\b(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\b\.){3}\b(\d|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\b
Результат выглядит так:
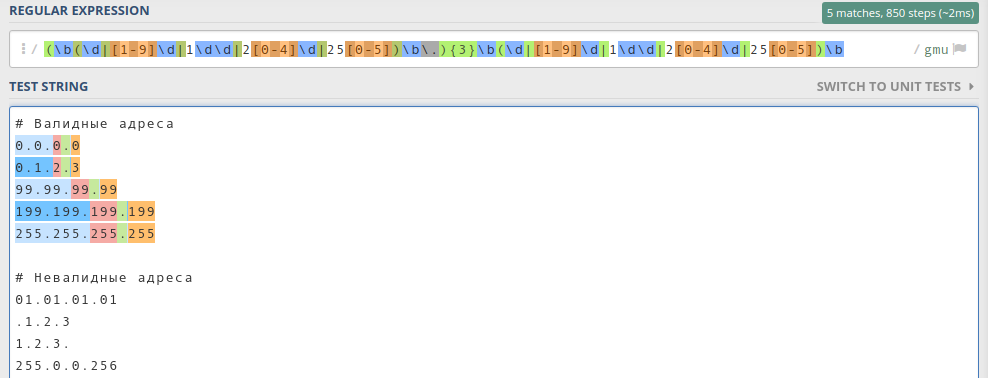
Подсветились только валидные ip-адреса, значит регулярное выражение работает корректно.
Если бы я сразу начал писать валидацию всего адреса, а не отдельного байта, то с большой долей вероятности допустил бы ошибку. Скопления скобочек, палочек и точечек трудно воспринимаются на глаз, поэтому задачу надо обязательно упрощать.
Практическое применение регулярных выражений ¶
Регулярными выражениями можно пользоваться не только для валидации, но и для обработки данных, например, в блокноте. Вот практический пример такой обработки: скопировать номера регионов и перевести в формат PHP-массива.
Ссылки ¶
- https://regex101.com/ - сайт для тестирования регулярных выражений.
- https://linux.die.net/man/1/perlre - руководство по регулярным выражениям Perl.
- https://www.php.net/manual/ru/reference.pcre.pattern.syntax.php - регулярные выражения в PHP.
- https://developer.mozilla.org/ru/docs/Web/JavaScript/Reference/Global_Objects/RegExp - регулярные выражения JavaScript.